Qwen3.6-35B-A3B MoE大模型消费级显卡实战(RTX4060 8G)
通义千问 Qwen3.6-35B-A3B + 视觉能力,8G 显存、32G 内存,Windows 部署
前言
大模型常被认为是高端显卡的专属,动辄 24G、48G 显存门槛劝退普通玩家。但随着 llama.cpp 高性能推理 + GGUF 量化 + MoE 混合专家架构 的成熟,8G 消费级显卡也能跑 35B 级大模型,甚至带视觉能力。
本文全程基于 RTX 4060 8G + 32G 内存 + Windows,手把手部署 Qwen3.6-35B-A3B MoE(含视觉),无编译、无高门槛、可直接照抄操作。
一、硬件与模型选型
1.1 硬件配置(真实消费级)
显卡:NVIDIA RTX 4060 8GB(GDDR6)
CPU:Intel i9-11900KB @ 3.30GHz
内存:32GB DDR4(双通道,关键!)
系统:Windows 11 64 位
1.2 选用模型详解
本次部署 通义千问 35B MoE 量化版 + 视觉投影:
主模型:
Qwen3.6-35B-A3B-UD-Q4_K_M.gguf(4-bit 量化,平衡速度 / 效果)视觉投影:
mmproj-BF16.gguf(支持图文对话、图片理解)
1.2.1 模型命名解析(A3B 与 UD)
| 字段 | 全称 | 核心含义 |
|---|---|---|
| Qwen3.6 | - | 通义千问 3.6 系列大模型 |
| 35B | 35 Billion | 模型总参数数量(MoE 架构) |
| A3B | Activated 3 Billion | 推理时每个 token 仅激活约 3B 参数,实际计算量接近 3B 模型 |
| UD | Unsloth Dynamic | Unsloth 团队优化的动态量化方案,兼顾高压缩率与推理质量 |
| Q4_K_M | 4-bit K-quant Medium | 4 比特分层量化,对关键层保留更高精度 |
| GGUF | - | llama.cpp 专用高效推理格式 |
1.2.2 选择理由
MoE 架构优势:总参数 35B,推理只激活少量专家,显存占用远低于同规模稠密模型
UD-Q4_K_M 量化:动态量化 + 混合精度,显存大幅下降,适配 8G+32G 配置
原生视觉能力:内置视觉编码器,开箱即用图文对话
开源生态成熟:Unsloth 提供 GGUF 版本,兼容性好、社区支持完善
二、环境安装(Windows,一键到位)
2.1 安装 CUDA 12.4(必须,13.2 有兼容问题)
管理员 PowerShell 执行:
1 | winget install NVIDIA.CUDA.12.4 |
安装完成后重启电脑。
2.2 下载预编译 llama.cpp(免编译)
下载:
llama-b9305-bin-win-cuda-12.4-x64.zip解压到目录,例如:
D:llama.cpp
2.3 安装 uv + huggingface-hub(uv tool)
2.3.1 安装 uv
1 | powershell -c "irm https://astral.sh/uv/install.ps1 | iex" |
2.3.2 安装 huggingface-hub
1 | uv tool install huggingface-hub |
验证:
1 | huggingface-cli --version |
2.4 永久配置 HF 国内镜像(hf-mirror)
镜像地址:https://hf-mirror.com
管理员 PowerShell 执行:
1 | setx HF_ENDPOINT "https://hf-mirror.com" /M |
或手动添加系统环境变量,重启终端生效。
2.5 下载模型(hf-mirror 加速)
进入 llama.cpp 目录,创建文件夹:
1 | mkdir -p models/Qwen3.6-35B-A3B-UD-Q4_K_M |
下载命令:
1 | hf download unsloth/Qwen3.6-35B-A3B-GGUF Qwen3.6-35B-A3B-UD-Q4_K_M.gguf mmproj-BF16.gguf --local-dir ./models/Qwen3.6-35B-A3B-UD-Q4_K_M |
三、启动脚本与参数详解(8G 最优配置)
在 llama.cpp 目录新建 start.bat:
1 | @echo off |
关键参数解析
| 参数 | 作用 | 适配说明 |
|---|---|---|
-ngl 99 |
99 层全部上 GPU | 最大化利用 4060 算力 |
--n-cpu-moe 32 |
MoE 专家放 CPU / 内存 | 显存不够、内存来补 |
--flash-attn on |
注意力加速 + 省显存 | 8G 必备优化 |
-c 32768 |
32K 上下文 | 支持长文本对话 |
--split-mode layer |
分层放显存 / 内存 | 防止爆显存 |
--cache-type-k/v q4_0 |
KV 缓存 4-bit 量化 | 显存占用减少 75% |
四、运行效果(8G 显卡真实表现)
4.1 启动与访问
双击
start.bat首次加载约 1–2 分钟
浏览器打开:http://127.0.0.1:8080
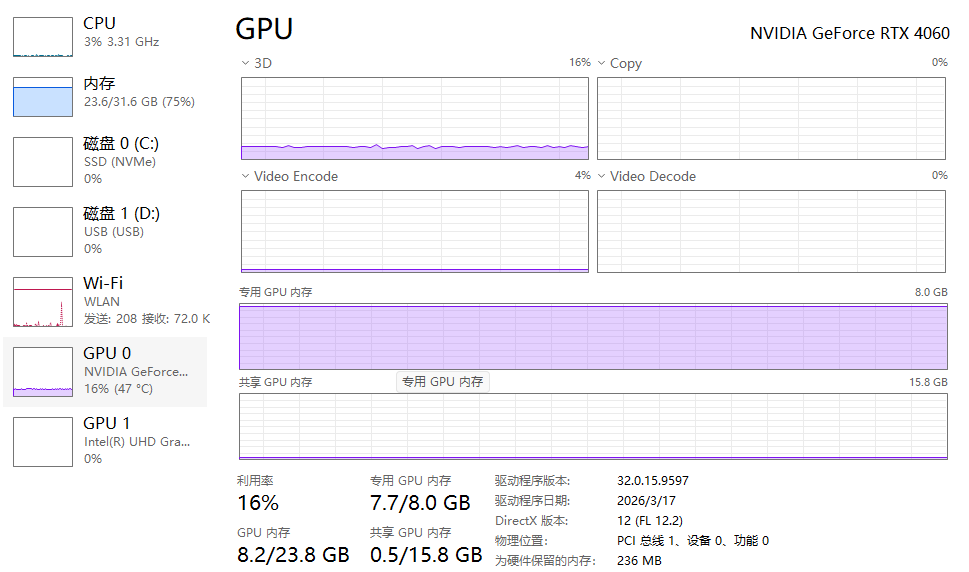
4.2 资源占用
显存:7.2–7.8GB(稳定不溢出)
内存:16–20GB(专家层分流)
CPU:90%(负载可控)
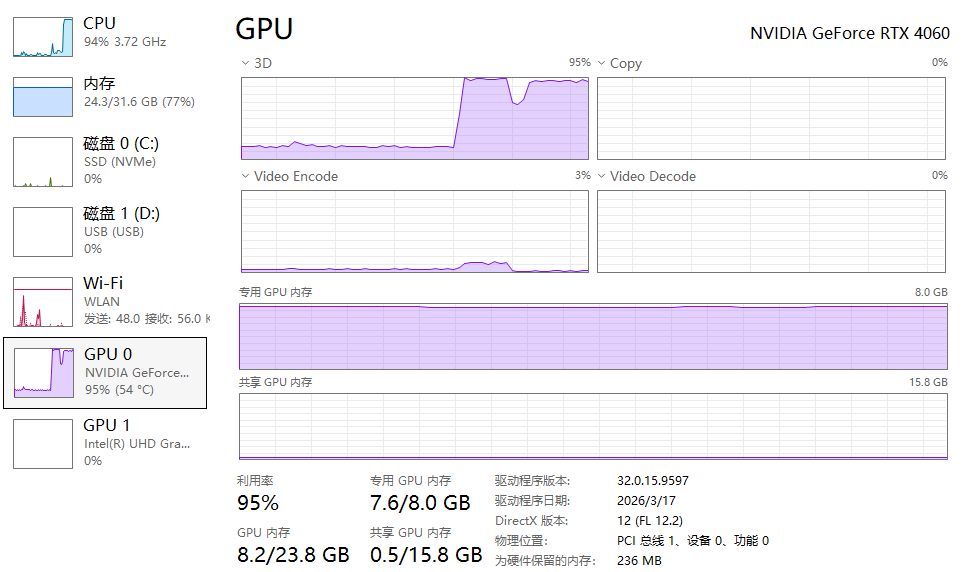
4.3 推理速度
文本对话:30 token/s(日常流畅)
图文对话:响应 2–3 秒,识别准确
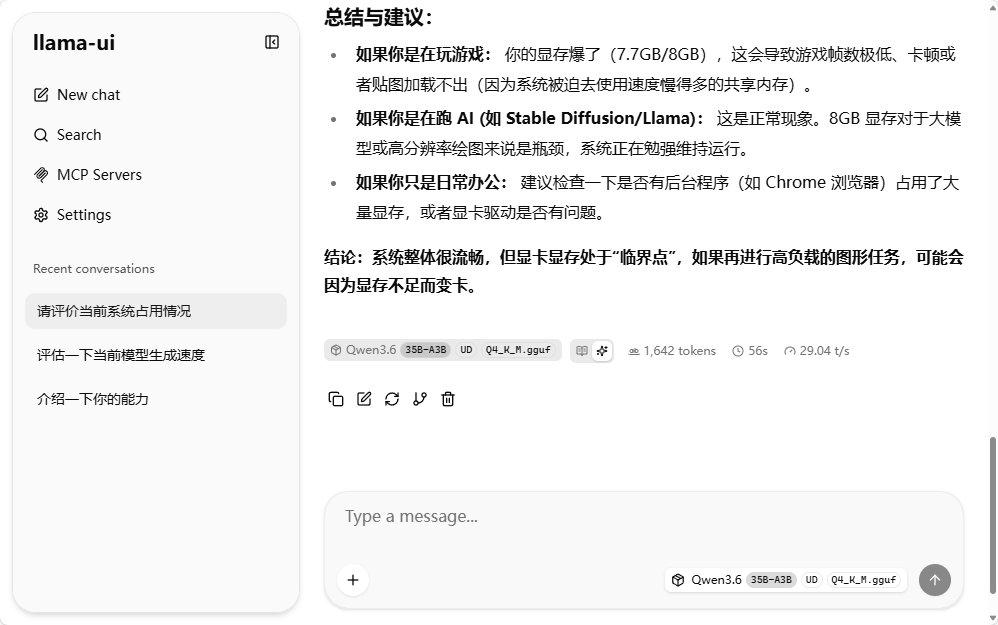
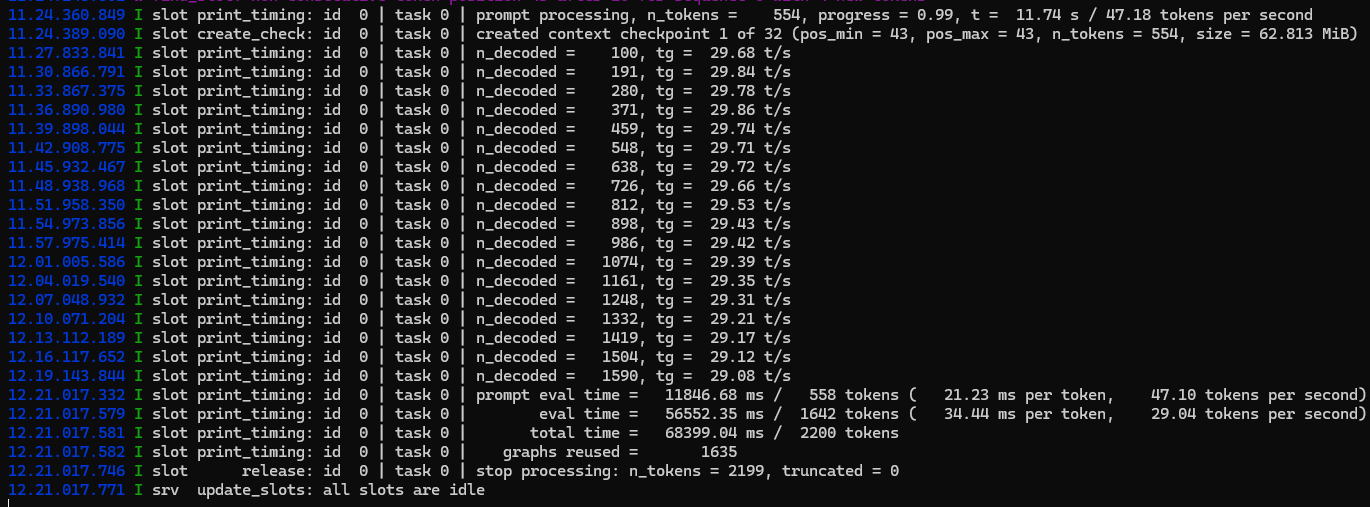
4.4 能力表现
文本:问答 / 推理 / 创作接近原生 35B
视觉:图片描述、OCR、简单图像问答可用
4.5 稳定性
连续运行 4 小时无崩溃,长文本对话不掉链。
五、效果截图
图 1:启动脚本运行成功界面
图 2:Web 交互主界面
图 3:GPU 显存占用监控
图 4:图文对话示例
六、总结
RTX 4060 8G 真的能跑 35B MoE + 视觉。核心要点:
CUDA 12.4 + llama.cpp 预编译,避开兼容问题
UD-Q4_K_M 量化 + KV 缓存量化,适配 8G 显存
MoE 专家分流到内存,32G 内存成为关键
hf-mirror 加速,国内高速下载模型
这套方案成本极低、操作极简、效果可用,普通消费卡也能体验 35B 级大模型能力。